Renxi Wang
Saturday, June 20, 2026
Bio
I am a PhD student at Natural Language Processing Department of Mohamed bin Zayed University of Artificial Intelligence (MBZUAI). I am fortunate to be supervised by Prof. Timothy Baldwin, Dr. Haonan Li, and Dr. Fajri Koto. My research interests include Natural Language Processing, Reinforcement Learning, and Large Language Model Agent.
I am actively looking for an internship related to foundation models' agent capabilities, including search, coding, computer-use, browser-use, etc.
Papers
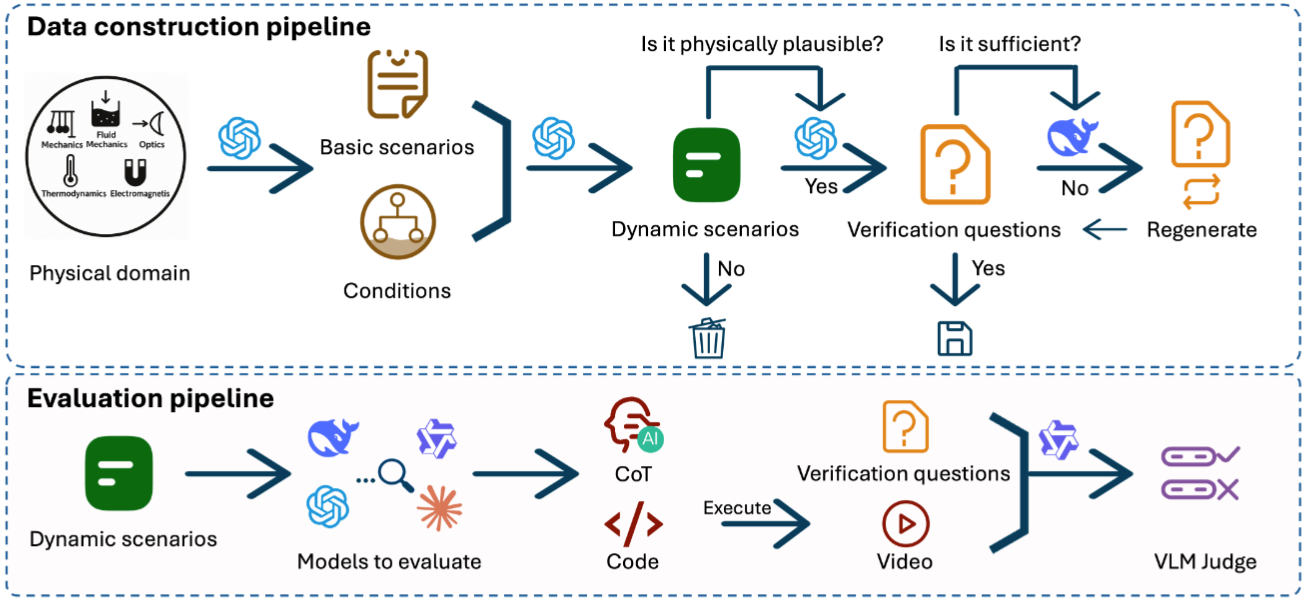
Training and Benchmarking Code Generation for Physics-Inspired Animations
Yanan Wang*, Renxi Wang*, Yongxin Wang*, Xuezhi Liang, Fajri Koto, Timothy Baldwin, Xiaodan Liang, Haonan Li
Under Review
Large language models (LLMs) have been widely studied in areas like math competitions, complex coding, and scientific reasoning. However, their ability to generate code that simulates physical phenomena and yields physics-inspired animations remains relatively underexplored. We propose SimuScene, the first systematic study that trains and evaluates LLMs on code generation for physics-inspired animations across five physics domains with 52 concepts. We built an automated data collection pipeline with human verification to ensure quality. The final dataset contains 7,659 scenarios with 334 human-verified examples as the test set. We evaluated 10 contemporary LLMs and found that even the strongest model achieves only a 21.5% pass rate, demonstrating task difficulty. Finally, we introduce a reinforcement learning pipeline with visual rewards that uses a vision-language model as a judge to train textual models. Experiments show that training with our data and visual rewards improves LLM performance on the task.
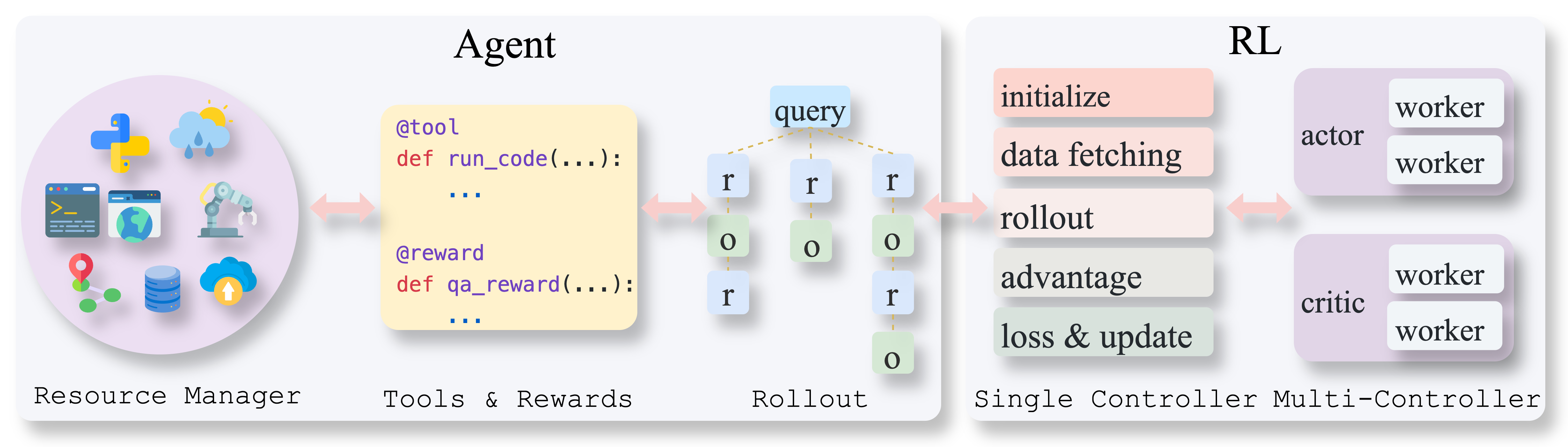
AgentFly: Extensible and Scalable Reinforcement Learning for LM Agents
Renxi Wang, Rifo Ahmad Genadi, Bilal El Bouardi, Yongxin Wang, Fajri Koto, Zhengzhong Liu, Timothy Baldwin, Haonan Li
arXiv
Language model (LM) agents have gained significant attention for their ability to autonomously complete tasks through interactions with environments, tools, and APIs. LM agents are primarily built with prompt engineering or supervised finetuning. At the same time, reinforcement learning (RL) has been explored to enhance LM’s capabilities, such as reasoning and factuality. However, the combination of the LM agents and reinforcement learning (Agent-RL) remains underexplored and lacks systematic study. To this end, we built AgentFly, a scalable and extensible Agent-RL framework designed to empower LM agents with a variety of RL algorithms. Our framework supports multi-turn interactions by adapting traditional RL methods with token-level masking. It features a decorator-based interface for defining tools and reward functions, enabling seamless extension and ease of use. To support high-throughput training, we implement asynchronous execution of tool calls and reward computations, and design a centralized resource management system for scalable environment coordination. We also provide a suite of prebuilt tools and environments, demonstrating the framework’s effectiveness through successful agent training across multiple tasks.
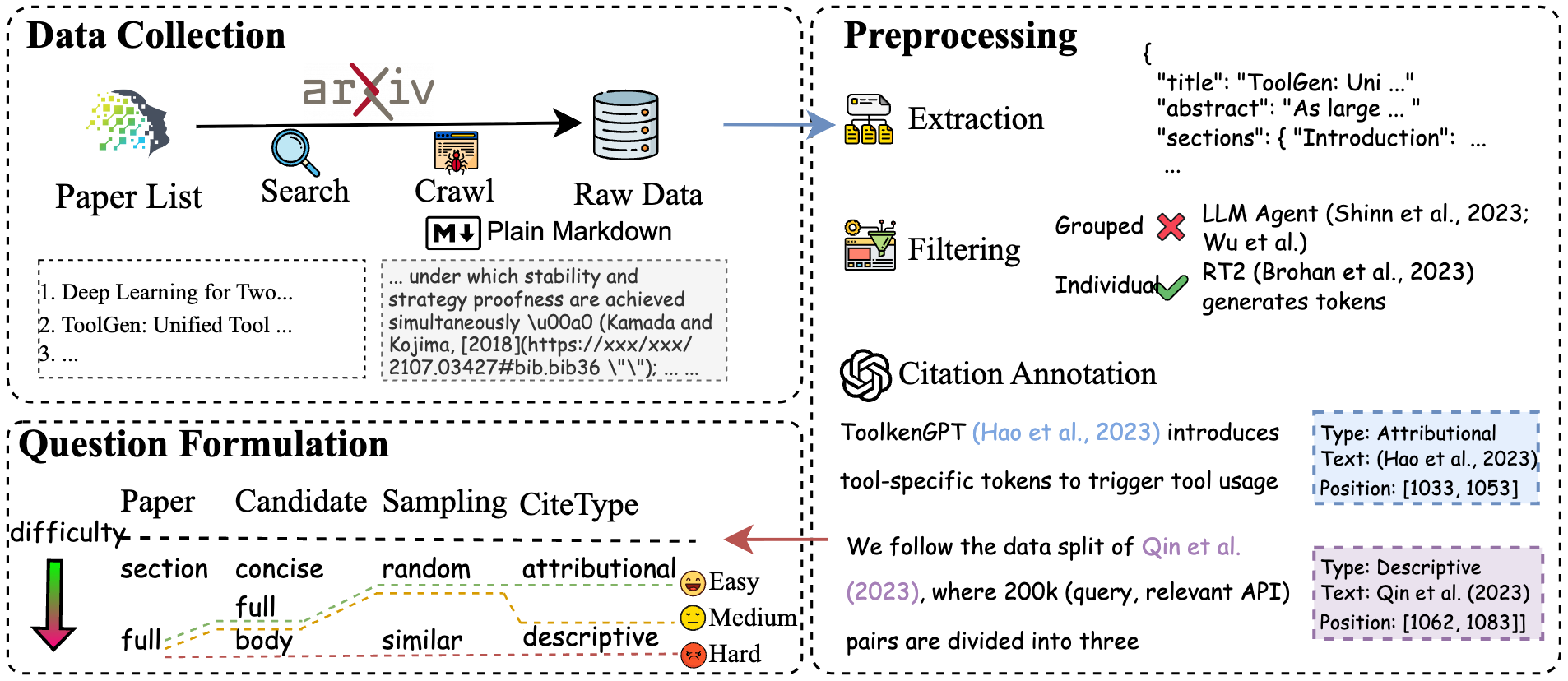
SCALAR: Scientific Citation-based Live Assessment of Long-context Academic Reasoning
Renxi Wang*, Honglin Mu*, Liqun Ma, Lizhi Lin, Yunlong Feng, Timothy Baldwin, Xudong Han, Haonan Li
EACL 2026
Long-context understanding has emerged as a critical capability for large language models (LLMs). However, evaluating this ability remains challenging. We present SCALAR, a benchmark designed to assess citation-grounded long-context reasoning in academic writing. SCALAR leverages academic papers and their citation structure to automatically generate high-quality ground-truth labels without human annotation. It features controllable difficulty levels and a dynamic updating mechanism that mitigates data contamination. The benchmark includes two tasks: a multiple-choice QA format and a cloze-style citation prediction. We evaluate a range of state-of-the-art LLMs and find that the multiple-choice task effectively distinguishes model capabilities---while human experts achieve over 90% accuracy, most models struggle. The cloze-style task is even more challenging, with no model exceeding 50% accuracy. SCALAR provides a domain-grounded, continuously updating framework for tracking progress in citation-based long-context understanding.
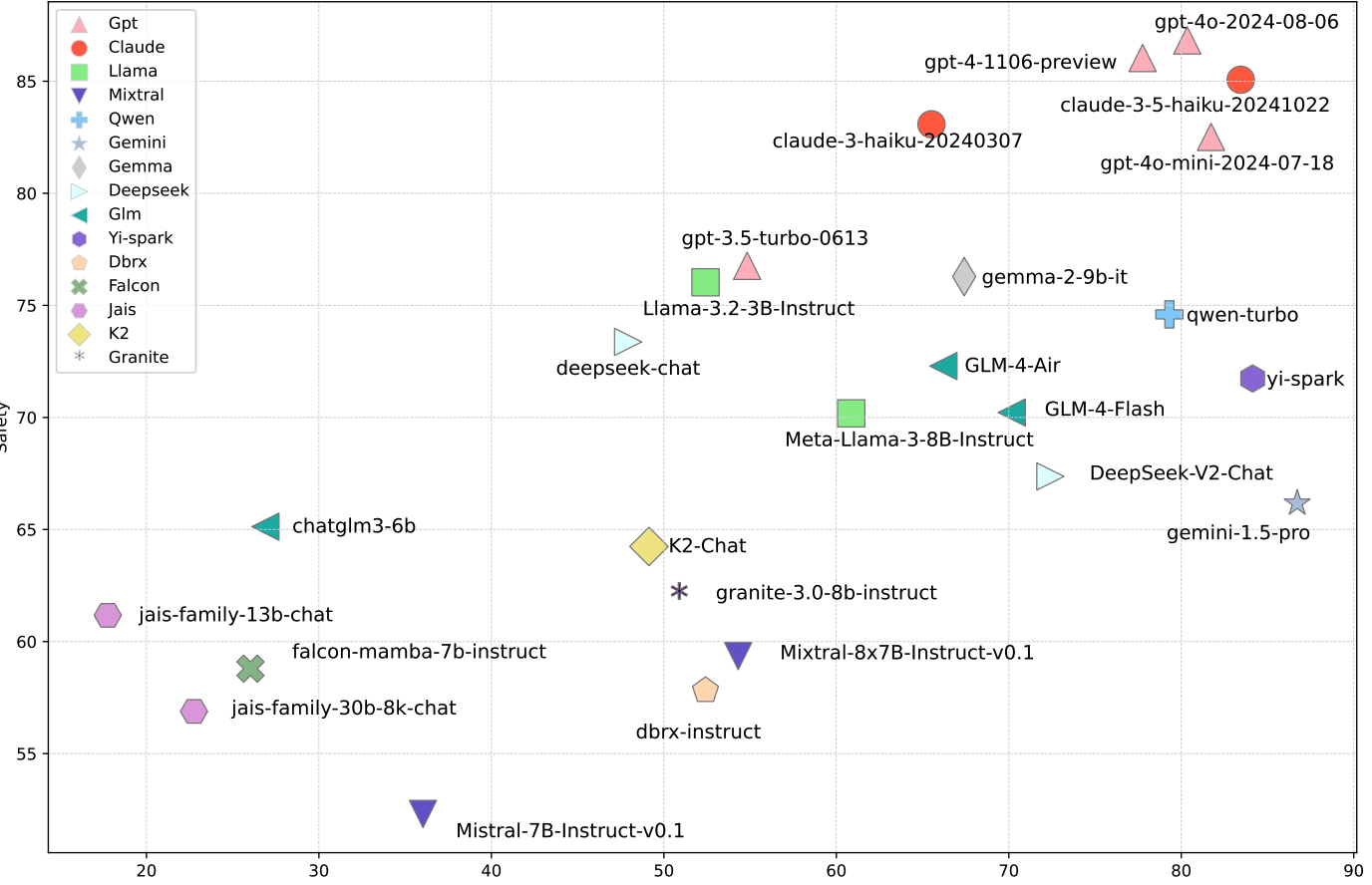
Libra-Leaderboard: Towards Responsible AI through a Balanced Leaderboard of Safety and Capability
Haonan Li, Xudong Han, Zenan Zhai, Honglin Mu, Hao Wang, Zhenxuan Zhang, Yilin Geng, Shom Lin, Renxi Wang, ...
NAACL 2025 Demo Track
As large language models (LLMs) continue to evolve, leaderboards play a significant role in steering their development. Existing leaderboards often prioritize model capabilities while overlooking safety concerns, leaving a significant gap inresponsible AI development. To address this gap, we introduce Libra-Leaderboard, a comprehensive framework designed to rank LLMs through a balanced evaluation of performance and safety. Combining a dynamic leaderboard with an interactive LLM arena, Libra-Leaderboard encourages the joint optimization of capability and safety. Unlike traditional approaches that average performance and safety metrics, Libra-Leaderboard uses a distance-to-optimal-score method to calculate the overall rankings. This approach incentivizes models to achieve a balance rather than excelling in one dimension at the expense of some other ones. In the first release, Libra-Leaderboard evaluates 26 mainstream LLMs from 14 leading organizations, identifying critical safety challenges even in state-of-the-art models.
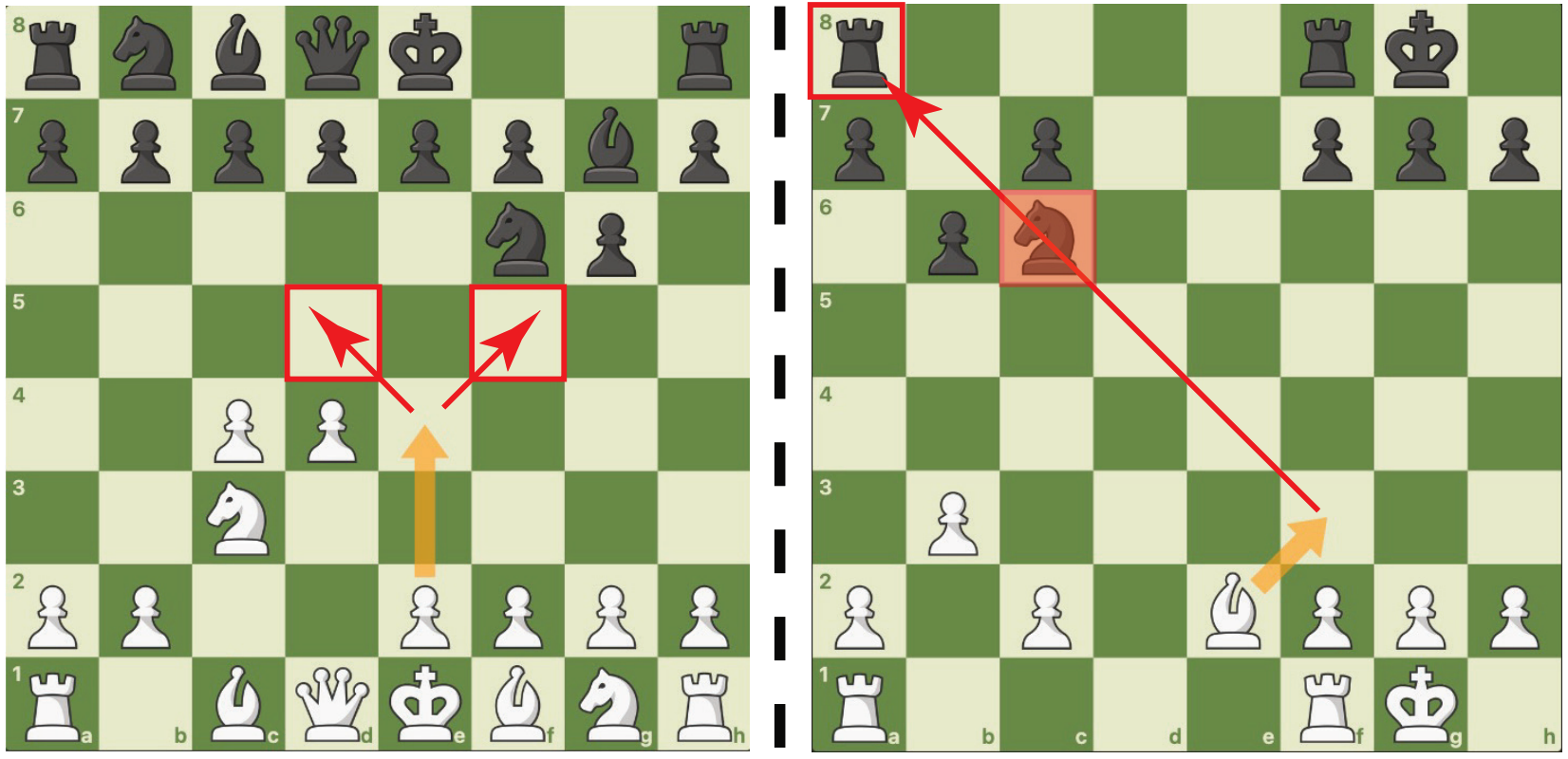
Explore the Reasoning Capability of LLMs in the Chess Testbed
Shu Wang, Lei Ji, Renxi Wang, Wenxiao Zhao, Haokun Liu, Yifan Hou, Ying Nian Wu
NAACL 2025
Reasoning is a central capability of human intelligence. In recent years, with the advent of large-scale datasets, pretrained large language models have emerged with new capabilities, including reasoning. However, these models still struggle with long-term, complex reasoning tasks, such as playing chess. Based on the observation that expert chess players employ a dual approach combining long-term strategic play with short-term tactical play along with language explanation, we propose improving the reasoning capability of large language models in chess by integrating annotated strategy and tactic. Specifically, we collect a dataset named MATE, which consists of 1 million chess positions with candidate moves annotated by chess experts for strategy and tactics. We finetune the LLaMA-3-8B model and compare it against state-of-the-art commercial language models in the task of selecting better chess moves. Our experiments show that our models perform better than GPT, Claude, and Gemini models. We find that language explanations can enhance the reasoning capability of large language models.
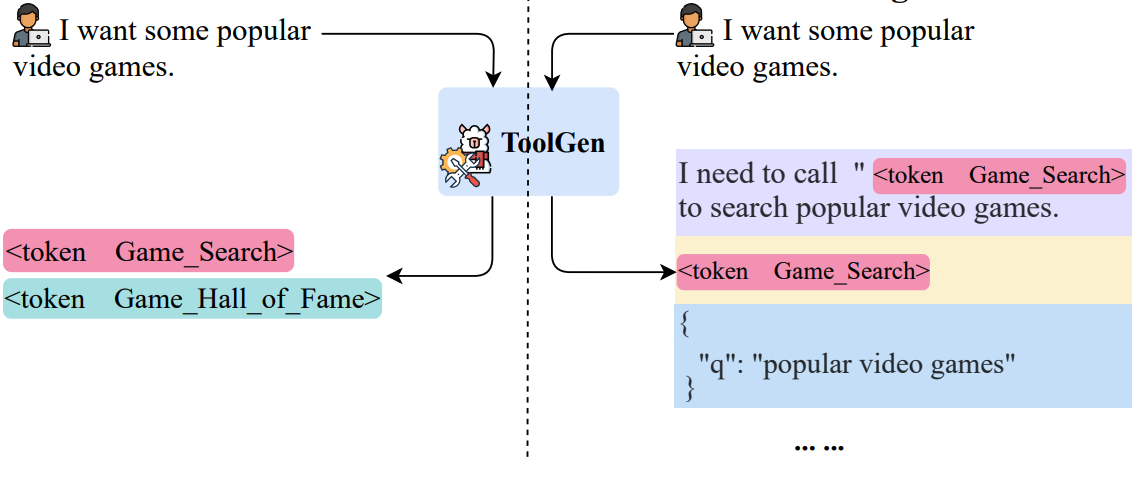
ToolGen: Unified Tool Retrieval and Calling via Generation
Renxi Wang, Xudong Han, Lei Ji, Shu Wang, Timothy Baldwin, Haonan Li
ICLR 2025
As large language models (LLMs) advance, their inability to autonomously execute tasks by directly interacting with external tools remains a critical limitation. Traditional methods rely on inputting tool descriptions as context, which is constrained by context length and requires separate, often inefficient, retrieval mechanisms. We introduce ToolGen, a paradigm shift that integrates tool knowledge directly into the LLM's parameters by representing each tool as a unique token. This enables the LLM to generate tool calls and arguments as part of its next token prediction capabilities, seamlessly blending tool invocation with language generation. Our framework allows the LLM to access and utilize a vast amount of tools with no additional retrieval step, significantly enhancing both performance and scalability. Experimental results with over 47,000 tools show that ToolGen not only achieves superior results in both tool retrieval and autonomous task completion but also sets the stage for a new era of AI agents that can adapt to tools across diverse domains. By fundamentally transforming tool retrieval into a generative process, ToolGen paves the way for more versatile, efficient, and autonomous AI systems. ToolGen enables end-to-end tool learning and opens opportunities for integration with other advanced techniques such as chain-of-thought and reinforcement learning, thereby expanding the practical capabilities of LLMs.
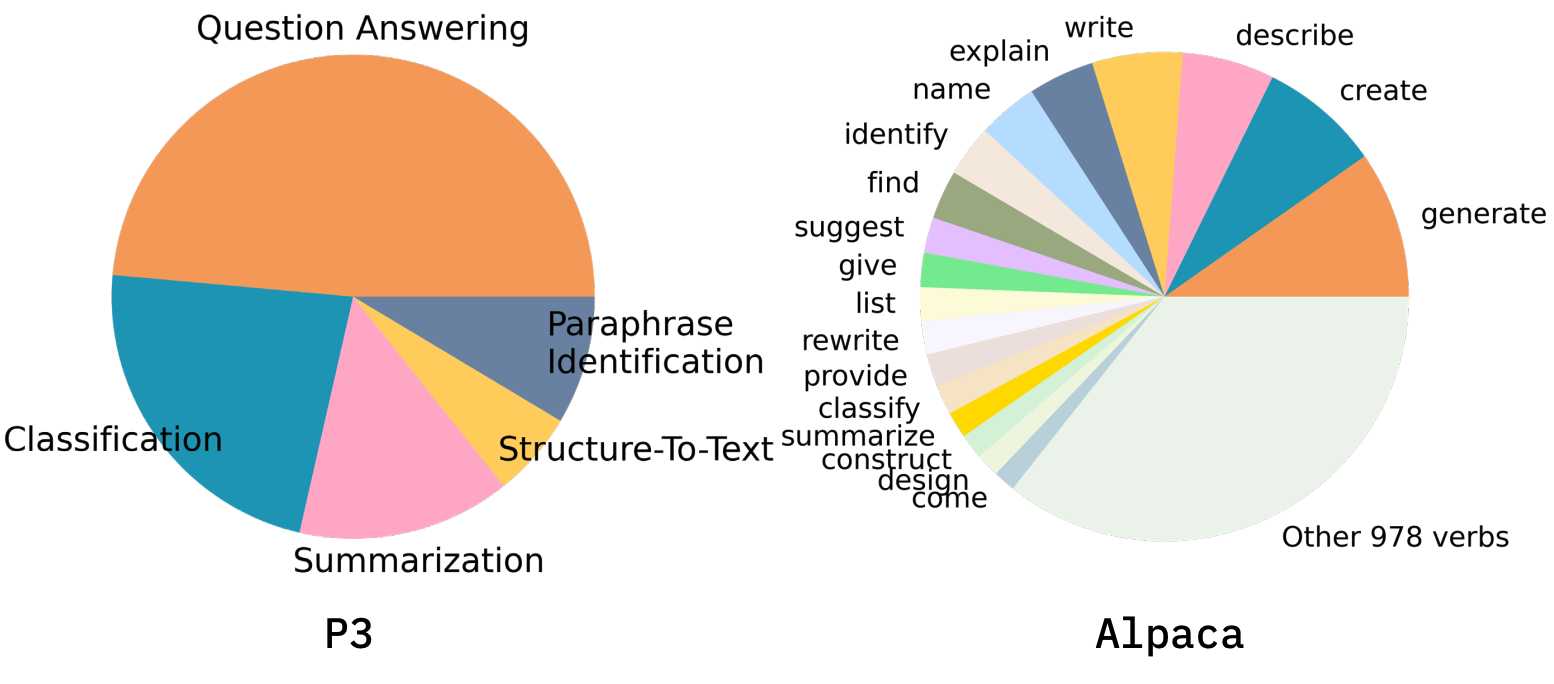
Demystifying Instruction Mixing for Fine-tuning Large Language Models
Renxi Wang, Haonan Li, Minghao Wu, Yuxia Wang, Xudong Han, Chiyu Zhang, Timothy Baldwin
ACL SRW
Instruction tuning significantly enhances the performance of large language models (LLMs) across various tasks. However, the procedure to optimizing the mixing of instruction datasets for LLM fine-tuning is still poorly understood. This study categorizes instructions into three primary types: NLP downstream tasks, coding, and general chat. We explore the effects of instruction tuning on different combinations of datasets on LLM performance, and find that certain instruction types are more advantageous for specific applications but can negatively impact other areas. This work provides insights into instruction mixtures, laying the foundations for future research.
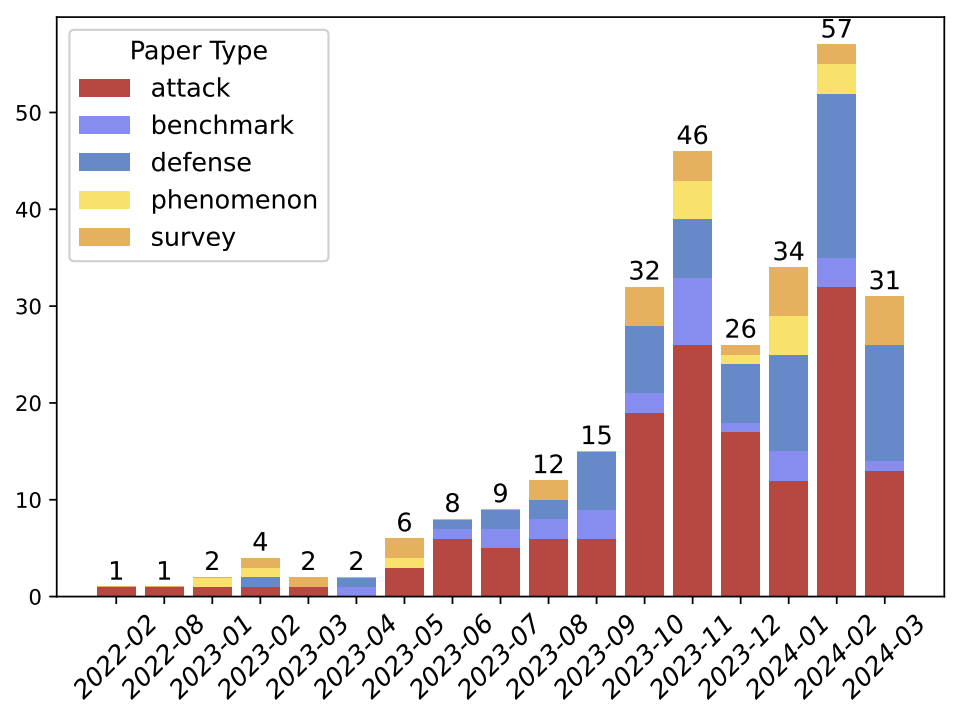
Against The Achilles' Heel: A Survey on Red Teaming for Generative Models
Lizhi Lin, Honglin Mu, Zenan Zhai, Minghan Wang, Yuxia Wang, Renxi Wang, Junjie Gao, Yixuan Zhang, Wanxiang Che, ...
JAIR
Generative models are rapidly gaining popularity and being integrated into everyday applications, raising concerns over their safe use as various vulnerabilities are exposed. In light of this, the field of red teaming is undergoing fast-paced growth, highlighting the need for a comprehensive survey covering the entire pipeline and addressing emerging topics. Our extensive survey, which examines over 120 papers, introduces a taxonomy of fine-grained attack strategies grounded in the inherent capabilities of language models. Additionally, we have developed the "searcher" framework to unify various automatic red teaming approaches. Moreover, our survey covers novel areas including multimodal attacks and defenses, risks around LLM-based agents, overkill of harmless queries, and the balance between harmlessness and helpfulness.
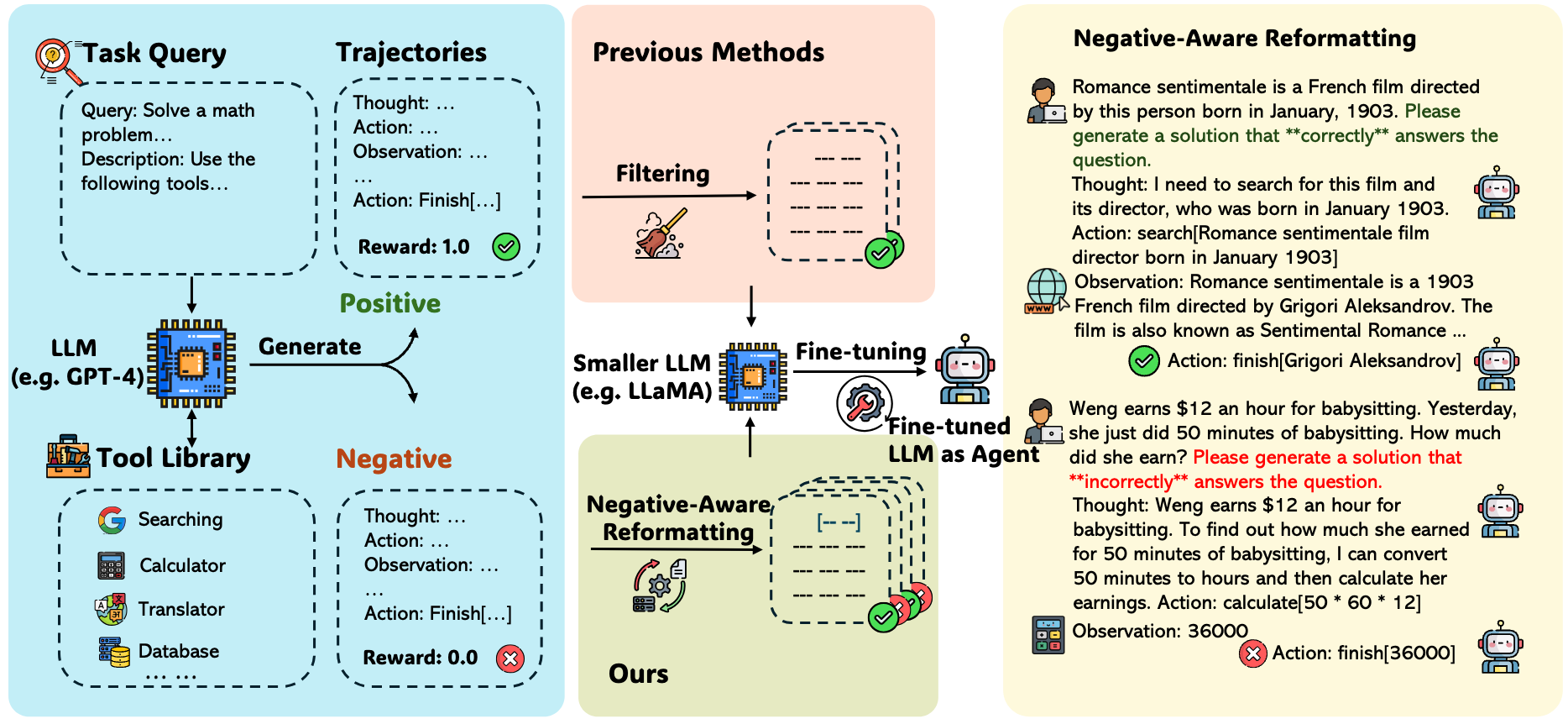
Learning From Failure: Integrating Negative Examples when Fine-tuning Large Language Models as Agents
Renxi Wang, Haonan Li, Xudong Han, Yixuan Zhang, Timothy Baldwin
NAACL 2025
Large language models (LLMs) have achieved success in acting as agents, which interact with environments through tools such as search engines. However, LLMs are optimized for language generation instead of tool use during training or alignment, limiting their effectiveness as agents. To resolve this problem, previous work has first collected interaction trajectories between LLMs and environments, using only trajectories that successfully finished the task to fine-tune smaller models, making fine-tuning data scarce and acquiring it both difficult and costly. Discarding failed trajectories also leads to significant wastage of data and resources and limits the possible optimization paths during fine-tuning. In this paper, we argue that unsuccessful trajectories offer valuable insights, and LLMs can learn from these trajectories through appropriate quality control and fine-tuning strategies. By simply adding a prefix or suffix that tells the model whether to generate a successful trajectory during training, we improve model performance by a large margin on mathematical reasoning, multi-hop question answering, and strategic question answering tasks. We further analyze the inference results and find that our method provides a better trade-off between valuable information and errors in unsuccessful trajectories. To our knowledge, we are the first to demonstrate the value of negative trajectories and their application in agent-tunning scenarios. Our findings offer guidance for developing better agent-tuning methods and low-resource data usage techniques.
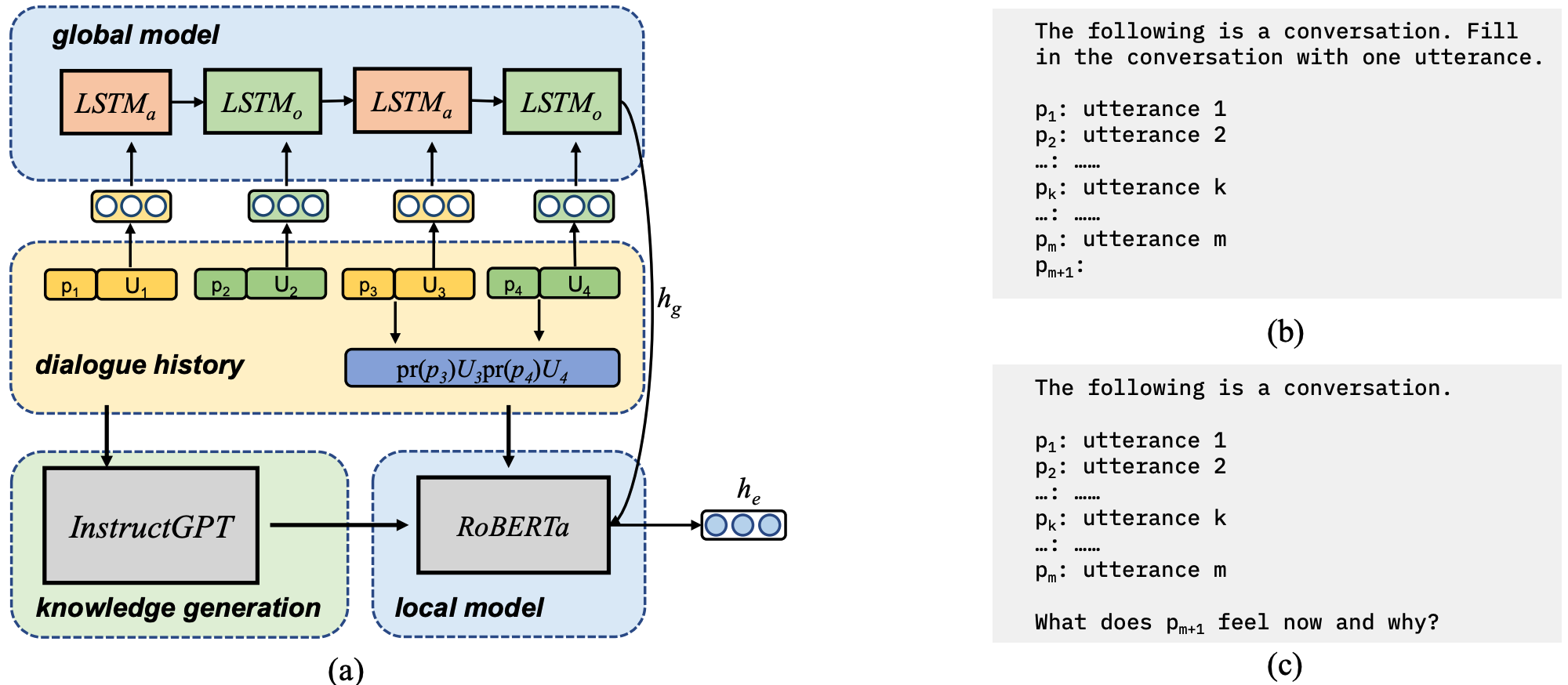
Global-Local Modeling with Prompt-Based Knowledge Enhancement for Emotion Inference in Conversation
Renxi Wang, Shi Feng
EACL Findings
The ability to recognize emotions in conversations is necessary and important for the online chatbot to do tasks such as empathetic response generation and emotional support. Present researches mainly focus on recognizing emotions through a speaker’s utterance, while research on emotion inference predicts emotions of addressees through previous utterances. Because of the lack of the addressee’s utterance, emotion inference is more challenging than emotion recognition. In this paper, we propose a global-local modeling method based on recurrent neural networks (RNN) and pre-trained language models (PLM) to do emotion inference, which utilizes the sequence modeling ability of RNNs and abundant knowledge from PLMs. Moreover, we take the whole dialogue history as input of PLM to generate knowledge by in-context learning. Experimental results show that our model with knoledge enhancement achieves state-of-the-art performance on all three datasets.
Experience

Mohamed bin Zayed University of Artificial Intelligence
MsC, PhD Student
2023 - 2025, 2025 - Present
Abu Dhabi, UAE

Microsoft Research Asia
Research Intern
Jun. 2024 - Sept. 2024
Beijing, China

Northeastern University, China
BSc Student
2019 - 2023
Shenyang, China